KerasのTensorNetworkを使用したニューラルネットワークの高速化
前書き
この投稿では、TensorNetworkと、それを使用してTensorFlowのフィードフォワードニューラルネットワークをスーパーチャージする方法について説明します。 TensorNetworkは、テンソルネットワークでの計算を容易にするために、19年6月にリリースされたオープンソースライブラリです。 通常、人々が私たちに最初に尋ねる質問は「テンソルネットワークとは何ですか?」であり、その次に「なぜテンソルネットワークを気にする必要があるのですか?」です。 最初の質問(以前のGoogle AIブログ投稿など)に対処する多くのリソースがあります。ここでは、2番目の質問に答えることに焦点を当てます。 基本的な考え方は、ニューラルネットワークの「テンソル化」と呼ばれ、2015年のNovikovらの論文にそのルーツがあります。 al。 TensorNetworkライブラリを使用すると、この手順を簡単に実装できます。 以下に、KerasとTensorFlow 2.0を使用した明示的かつ教育的な例を示します。
TensorNetworkを使い始めるのは簡単です。 ライブラリは、pipを使用してインストールできます:
pip install tensornetwork
TN Layers
TN拡張ニューラルネットワークの基本的な考え方は、ネットワークの1つ以上のレイヤーをTNレイヤーに置き換えることです。 TNレイヤーは、元のレイヤーの圧縮バージョンと考えることができます。 最適な結果は、圧縮の可能性が高い高密度で接続性の高いレイヤーで開始するときに期待できます。 たとえば、次のことを考慮してください:
Dense = tf.keras.layers.Dense
fc_model = tf.keras.Sequential(
[
tf.keras.Input(shape=(2,)),
Dense(1024, activation=tf.nn.swish),
Dense(1024, activation=tf.nn.swish),
Dense(1, activation=None)])
このネットワークには2次元の入力、1次元の出力があり、それぞれ1024個のニューロンを持つ2つの隠れ層が含まれています。 パラメーターの総数(重みとバイアスを含む)は、(2 + 1)* 1024 +(1024 + 1)* 1024 +(1024 +1)* 1 = 1,053,697です。 これらのパラメータの大部分、(1024 + 1)* 1024 = 1,049,600は、2番目の非表示層に関連付けられています。 これらを元のサイズの1%未満のTNレイヤーに置き換えます。
隠れ層の1,049,600パラメーターは、1024 x 1024 = 1024 x 1024のマトリックスに配置された1,048,576の重みと1024のバイアスで構成されます。 1024 x 1024の重み行列をテンソルネットワークに置き換えることで節約できます。 ネットワークの他の部分との互換性を保つために、1024個の入力と1024個の出力があるという事実を変更しません。 そのようにして、TNレイヤーを元のレイヤーのドロップイン置換として扱うことができます。
通常、レイヤーへの1024入力は、形状の単純な配列X(1024、)と考えます。 これらの入力に重み行列Wを掛けて、新しいベクトルYを生成します。次のステップはYに非線形性を適用することですが、TNの変更はレイヤーの線形部分にのみ影響するため、それには焦点を当てません。 テンソルネットワーク表記では、Yの計算を次のように記述します:
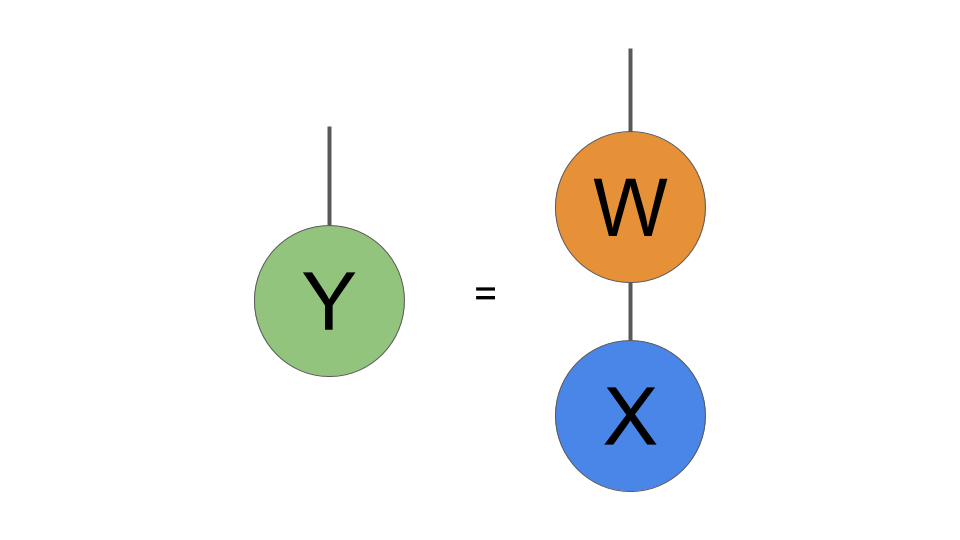
通常、ニューラルネットワーク層の重みWは入力Xに行列乗算として作用し、出力Y = WXを生成します。 ここで、その行列乗算を図式的に示します。
この時点で、レイヤーのテンソル化について説明できます。 まず、入力配列を(1024、)の代わりに(32,32)のような形に変更します。 図では、形状の変更は次のようになります:
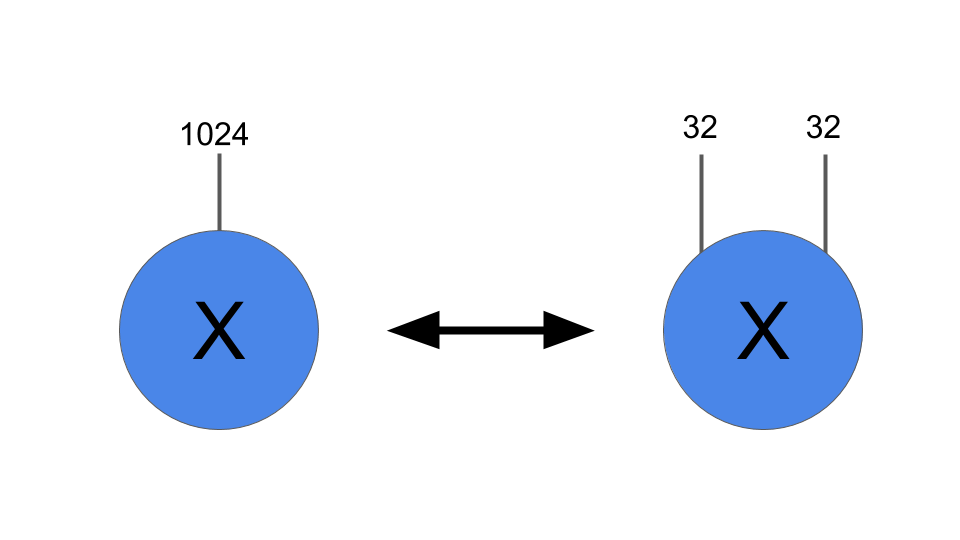
入力Xを形状のベクトル(1024、)から形状の配列(32,32)に変形することが、テンソル化プロセスの最初のステップです。 原則として、任意の形状変更が許可されています。この例では、この特に単純な形状を選択しました。
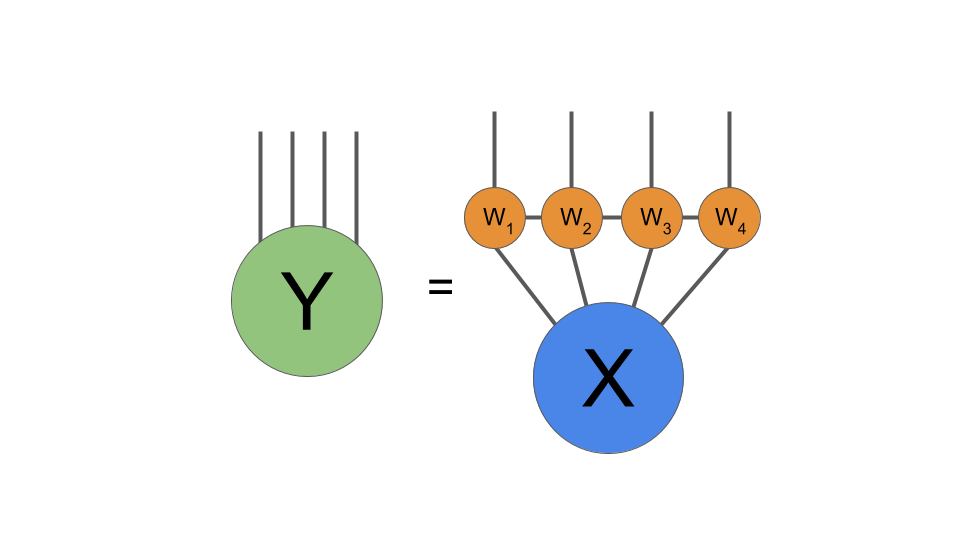
ここで、(1024,1024)重み行列Wを適用する代わりに、2つのコアで構成されるテンソルネットワーク操作を適用します:テンソル化された重み乗算の図式表現。 必要に応じて、出力Yをベクトルに再形成できます。
2つのコアを接続する脚の次元(結合次元と呼ばれることが多い)について選択する必要があります。 簡単にするために、2次元であると見なします。 次に、各コアには2つの30の2次元脚と1つの2次元脚があり、形状は(32,32,2)になります。 結合次元はモデル内のパラメーターの数を制御し、結合次元を適切に選択することにより、多くの場合、パフォーマンスの低下がほとんどまたはまったくない、良好なパラメーター削減率を実現します。
TNレイヤーを使用した結果、1,048,576個の完全に接続された重み行列の重みを、テンソルネットワークの2 *(32 * 32 * 2)= 4,096パラメーターに置き換えました。 それはものすごい削減です! 他のレイヤーを考慮した後でも、元の1,053,697と比較して、モデルの合計サイズは9,217個のパラメーターになります。
この簡単な例では、2コアテンソルネットワークをeinsum式に変換するのはそれほど難しくありません。 ただし、より多くのコアとより複雑な接続を持つテンソルネットワークの場合、einsumのデバッグまたは拡張は非常に困難です。 したがって、代わりに、ネットワークを構築するよりオブジェクト指向の方法のためにTNライブラリを使用します。 以下のコード例では、わかりやすいように単純な2コアの例に固執しますが、最後に戻って他の可能性について説明します。
Code for a TN Layer
上記の1024 x 1024のケースに特化したKerasでTNレイヤーを作成するためのサンプルコードを次に示します:
import tensorflow as tf
import tensornetwork as tn
class TNLayer(tf.keras.layers.Layer):
def __init__(self):
super(TNLayer, self).__init__()
# Create the variables for the layer.
self.a_var = tf.Variable(tf.random.normal(
shape=(32, 32, 2), stddev=1.0/32.0),
name="a", trainable=True)
self.b_var = tf.Variable(tf.random.normal(shape=(32, 32, 2), stddev=1.0/32.0),
name="b", trainable=True)
self.bias = tf.Variable(tf.zeros(shape=(32, 32)), name="bias", trainable=True)
def call(self, inputs):
# Define the contraction.
# We break it out so we can parallelize a batch using
# tf.vectorized_map (see below).
def f(input_vec, a_var, b_var, bias_var):
# Reshape to a matrix instead of a vector.
input_vec = tf.reshape(input_vec, (32,32))
# Now we create the network.
a = tn.Node(a_var, backend="tensorflow")
b = tn.Node(b_var, backend="tensorflow")
x_node = tn.Node(input_vec, backend="tensorflow")
a[1] ^ x_node[0]
b[1] ^ x_node[1]
a[2] ^ b[2]
# The TN should now look like this
# | |
# a --- b
# \ /
# x
# Now we begin the contraction.
c = a @ x_node
result = (c @ b).tensor
# To make the code shorter, we also could've used Ncon.
# The above few lines of code is the same as this:
# result = tn.ncon([x, a_var, b_var], [[1, 2], [-1, 1, 3], [-2, 2, 3]])
# Finally, add bias.
return result + bias_var
# To deal with a batch of items, we can use the tf.vectorized_map
# function.
# https://www.tensorflow.org/api_docs/python/tf/vectorized_map
result = tf.vectorized_map(
lambda vec: f(vec, self.a_var, self.b_var, self.bias), inputs)
return tf.nn.relu(tf.reshape(result, (-1, 1024)))
In this example, we hard-coded the size of the layer, but that is fairly easy to adjust. Having made this layer, we can use it as part of a Keras model very simply:
tn_model = tf.keras.Sequential(
[
tf.keras.Input(shape=(2,)),
Dense(1024, activation=tf.nn.relu),
# Here use a TN layer instead of the dense layer.
TNLayer(),
Dense(1, activation=None)
]
)
モデルは、Keras fitを使用して通常どおりトレーニングできます。
トランスなどの圧縮
上で説明した簡単な例は、テンソル化のアイデアの良い例ですが、その特定のモデルはおそらく実際にはあまり役に立ちません。 より現実的なものとして、最近、非常によく似た方法でTransformerモデルをテンソル化する実験を行いました。 私たちが見たモデルには、はるかに大きな密度の層がありました。元のモデルには236Mのパラメーターがありました! 4コアテンソルネットワークを備えた8つのTransformerブロックの完全に接続されたレイヤーをテンソル化しました:
テンソル化後、モデルは約101Mパラメーターに縮小しました! テンソル化モデルは、はるかに小さいことに加えて、英語の文を大幅に高速で生成しました。 これは、パフォーマンスの違いを示すビデオです。
ニューラルネットワークのさまざまなタイプのレイヤーに適用できる他のタイプのテンソルネットワークとテンソル分解がいくつかありますが、ここでは完全な参照リストを提供しようとはしません。 しかし、はじめに、Khrulkov et alをチェックしてください。 埋め込み層のテンソルネットワーク、Ma et al。 注意層のため、およびレベデフ等。 畳み込み層用。
ニューラルネットワークのテンソル化はまだ初期段階です。 まだ多くの未回答の質問があり、試行すべき多くの実験があります。 この投稿で検討するすべてのテンソルネットワークは、物理学ではMPO(このペーパーも参照)として知られているテンソル列タイプですが、PEPSやMERAなどの他のよく研究されたテンソルネットワークも使用できます。 TensorNetworkライブラリは、可能性のあるすべてのテンソルネットワークを処理するように設計されており、特にここで説明したように、機械学習のコンテキストで処理するように設計されています。 私たちは、あなたがそれを使って料理できる新しい刺激的な結果のすべてを見るのを楽しみにしています。(からのソース: https://blog.tensorflow.org/2020/02/speeding-up-neural-networks-using-tensornetwork-in-keras.html)
彩蛋:
GravitylinkはGoogle Coralの量販代理店としてアジア、北米、欧州、その他の国・地域に広がる世界的販売網を構築している。その開始以来、多数の企業が生産開発のため、GravitylinkオンラインストアでCoralデバイスの大量購入をしている。
詳細はhttps://store.gravitylink.com/ を参照。大量購入については割引が可能で、さらにどの製品でもGravitylinkで購入すれば、移行学習ツールやさまざまなAIモデルリソースが提供される。
GravitylinkがGoogleの新しいCoral製品を発売、企業のローカルAIソリューション構築を支援

GravitylinkはGoogle Coralの量販代理店としてGoogle Coral Edge TPUの全てのシリアルデバイスを発売する。Coralは、企業がローカルAIの製品を開発するのを支援するための完全なツールキットであり、エッジデバイス上のニューラルネットワークにハードウエア加速をもたらす。
高効率、非公開、高速、オフラインのオンデバイス機能により、多くの企業は、ヘルスケア、スマートシティー、輸送から製造、STEM(科学、技術、工学、数学)教育などに及ぶ多様なアプリケーションを構築するため、その使用を開始している。
顧客のニーズに応えるため、Coralはプロトタイピング(試作品製造)から生産に至るまでのデバイス類を提供しており、これはスタートアップや大企業にとって十分に柔軟性がある。
プロトタイピングデバイスには、Dev Board(Miniバージョンが近くリリース予定)とUSB Acceleratorが含まれている。これらのデバイスを利用すれば、試作品のアイデアをスケッチから概念実証に移すのは容易である。
生産の整ったデバイスには、システムオンモジュール、3種類のPCIeモジュール、および近くリリース予定の新製品Accelerator Moduleが含まれている。これらのデバイスはどんな規模でも途切れなくプロセスに一体化され、諸産業にとって状況に応じたソリューションを開発するのに役立つ。
さらに、Google CoralはカメラモジュールとEnvironmental Sensor Boardの2種類の検知製品もリリースした。
GravitylinkはGoogle Coralの量販代理店としてアジア、北米、欧州、その他の国・地域に広がる世界的販売網を構築している。その開始以来、多数の企業が生産開発のため、GravitylinkオンラインストアでCoralデバイスの大量購入をしている。
詳細はhttps://store.gravitylink.com/ を参照。大量購入については割引が可能で、さらにどの製品でもGravitylinkで購入すれば、移行学習ツールやさまざまなAIモデルリソースが提供される。
TensorFlowとEdge TPUによる犬の訓練
GoogleのTensorFlowLite(およびEdgeTPU)を使用すると、イヌを自律的に訓練して、座ったり、横になったり、固定したり、呼び出したりするなど、さまざまな行動に応答させることができます。 これにより、すべての犬が低コストで訓練され、犬の生活が豊かになり、経済的にストレスの多い救助ステーションと低い採用率にプラスの影響がもたらされると考えています。 Google EdgeTPUを使用すると、犬がデバイスとやり取りするときの動作を理解し、学習できます。

TensorFlowで動物を理解する
同様に、犬の訓練は、犬が放つ信号と行動をよく理解することに焦点を当てています。
TPUが知覚問題の解決にどのように役立つかを理解するには、犬のハンドラーが犬の行動を理解する上で重要だと考える情報を理解する必要があります。以下は、犬の訓練中に犬の飼い主が尋ねる質問です。

犬はおやつを食べていますか?
犬は「座る」アクションを実行していますか?
犬はすでに「横になっている」コマンドを知っていますか?
犬は以前に訓練されたことがありますか?
環境の犬は一般的にどこに滞在することを選択しますか?
犬は私からどのくらい離れていますか?
犬は私を追いかけていますか?
犬は「座る」アクションを実行していますか?
犬はすでに「横になっている」コマンドを知っていますか?
犬は以前に訓練されたことがありますか?
環境の犬は一般的にどこに滞在することを選択しますか?
犬は私からどのくらい離れていますか?
犬は私を追いかけていますか?
これらの質問に答えるために、機械学習、より具体的にはディープラーニングの使用を選択しました。 ディープラーニングは、これらの人間の知覚に関連する問題を解決するのに優れており、時間の経過とともに関連する行動パターンを探します。 したがって、ディープラーニングはコンピュータービジョンや自然言語処理の分野でも広く使用されています。
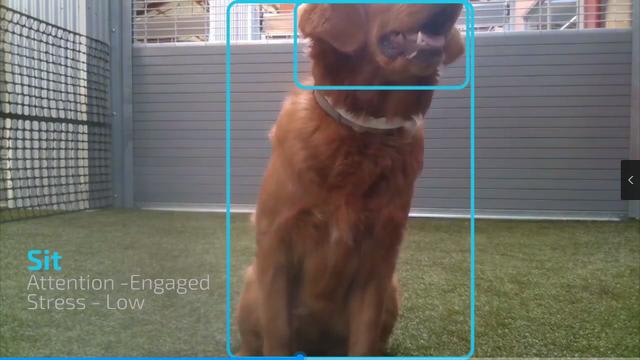
次に、すべてのシグナルを収集し、興味のあるものを見つけます。 私たちの動物行動チームは、犬の訓練に対する準備を理解するために収集したいすべての体のポーズと音をリストしました。
強力なコンピュータービジョンニューラルネットワークをトレーニングするために、TensorFlowを深層学習プラットフォームとして使用することにしました。 同じタスクで、GoogleのクラウドTPUを使用してネットワークをトレーニングする方が、複数のGPUを使用するよりも速くて安価です。 次に、デスクトップデバイスを使用してGPUでトレーニング済みモデルをローカルで実行し、犬のリアルタイムの動作を判断してトレーニングできます。 私たちのモデルは、犬のボディーランゲージと音を分析することにより、犬の現在の状態を理解し、相互作用します。
犬の行動をリアルタイムで理解して対応するために、ニューラルネットワークをサポートするのに必要な計算能力を備えた適切なモバイルプラットフォームを探しています。 いくつかのモバイルプラットフォームを評価した後、TensorFlowのモバイル製品TensorFlow Liteを実行できるGoogleのEdgeTPUを選択しました。 モバイルコンピュータビジョンモデルはGoogle EdgeTPUでも利用可能であり、以前のシステムよりも4倍高速に動作することがわかりました。

Google Edge TPU 海外代理店:https://store.gravitylink.com/global
Gravitylinkで任意の製品を購入すると、50以上のMLモデルを取得し、学習ツールを無料で移行できます.
評価:Google Coral USBアクセラレーターとIntel NCS 2
人工知能(AI)と機械学習(ML)は徐々にSFから実生活へと移行しており、このタイプのシステムのプロトタイプを作成するための高速で便利な方法が必要になっています。 AI / MLの操作要件を満たすにはデスクトップコンピューターでも十分ですが、Raspberry Piなどのシングルボードコンピューターでもこれらのニーズを満たすことができます。 しかし、システムをより速く、より強力に実行するためのシンプルなプラグインデバイスが必要な場合はどうでしょうか。
GoogleのCoral Edge TPUシリーズハードウェアUSBアクセラレーター(Coral USB Accelerator、CUA)やIntelのNeural Compute Stick 2(ニューラルコンピューティングスティックNCS2)など、実際には複数の選択肢があります。 両方のデバイスは、USB経由でホストに接続されたコンピューティングデバイスです。 NCS2は視覚処理ユニット(VPU)を使用し、Coral USB Acceleratorはテンソル処理ユニット(TPU)を使用します。どちらも機械学習用の特殊な処理デバイスです。 今日、私は皆を比較し、評価します:2つの違いは何ですか? 開発者として、CoralまたはNCS2を選択する必要がありますか? 言うまでもなく、以下を参照してください。
Coral USBアクセラレーター
-MLアクセラレータ:Googleが設計したEdge TPU ASIC(特定用途向け集積回路)チップ。 TensorFlow Liteモデル(MobileNet V2 400 + fps、最新の公式更新データから)専用の高性能ML推論を提供します。

(Google Coral Edge TPU海外代理店売る:Gravitylink
- USB 3.1ポートとケーブルをサポート(SuperSpeed、5GB / s転送速度)
- サイズ:30 x 65 x 8 mm
- 公式価格:$ 74.99
Intel Neural Compute Stick 2
-プロセッサー:Intel Movidius Myriad X Visual Processing Unit(VPU)
- USB 3.0 Type-A
- サイズ:72.5 x 27 x 14mm
- 公式価格:$ 87.99

まず、プロセッサと加速性能の比較
従来のコンピューターCPUと比較する場合とは異なり、各プロセッサー/アクセラレーターの比較の詳細は、それらの使用方法によって異なります。出力形式はわずかに異なりますが(フレームあたりの推論時間と1秒あたりのフレーム数)、いくつかの全体的なパフォーマンスモードで2つのデバイスを比較できます。
リアルタイム展開のためにAIモデルとハードウェアプラットフォームを評価する場合、最初に確認することは、それらがどれほど速いかです。コンピュータービジョンタスクでは、ベンチマークは通常、フレーム/秒(FPS)で測定されます。数値が大きいほどパフォーマンスが向上することを示し、ライブビデオストリーミングの場合、ビデオをスムーズに表示するには少なくとも約10 fpsが必要です。
運用パフォーマンス:まず、CUAをデスクトップCPUに追加すると、パフォーマンスは約10倍向上し、運用パフォーマンスは比較的良好です。 (選択したCPUモデルによると、10倍のパフォーマンスはわずかに変動します。)NCS2は古いAtomプロセッサーと「連携」します。これにより、処理速度がほぼ7倍になります。ただし、より強力なプロセッサで使用した場合、NCS2によって提示される結果は驚くことではありません。
NCS2は、理論的に4 TOPSで推論を実行できます。奇妙なことに、CUAもまったく同じ速度ですが、MLを実行するために両方とも異なる操作を使用します。さらに、Intelは、NCS2が元のNeural Compute Stickの8倍強力であると主張しています。 (必要に応じて、価格は低くなりますが、元のニューラルコンピューティングスティックの代わりにNCS2を選択できます。)
公式ベンチマークレビュー

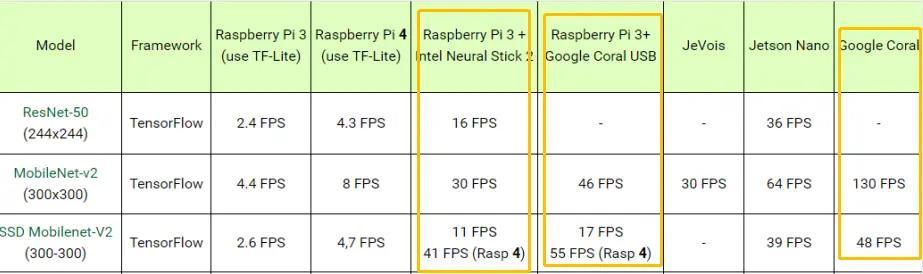
NCS2は、MobileNet-v2を使用して30 FPS分類モデルを実行できますが、これは悪くありません。 ただし、11 FPSでのオブジェクト検出は少し難しいです。 約10 FPSのフレームレートは、リアルタイムオブジェクトの追跡、特に高速モーションには不十分な場合があり、多くのオブジェクトが失われる可能性があり、開発者はこの「穴」を補うために非常に優れた追跡アルゴリズムを必要とします。 (もちろん、公式のベンチマーク結果は完全に信頼できるものではありません。多くの場合、これらの企業は、手動で最適化されたソフトウェアを競合他社の標準モデルと比較します。)
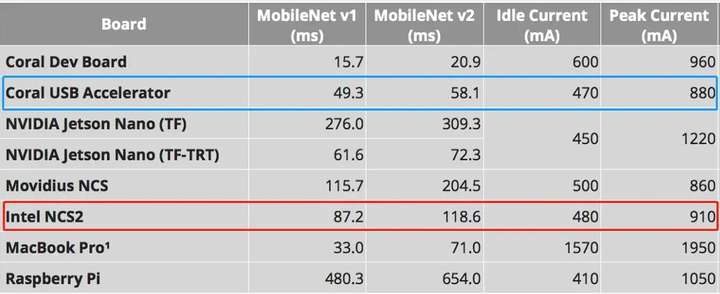
電力消費:NCS2はより少ない電力を消費します。 CUAの場合、当局は各TOPSに必要な0.5ワットをリストしています。 ユーザーは、必要に応じてCUAをデフォルトの速度または最大値(デフォルト値の2倍)に設定することもできます。
Googleの公式ドキュメントでは、デバイスが最高速度で動作し、最高周囲温度で動作しているときの電力伝送により皮膚が火傷する可能性があることを明確に警告しています。 個人的には、特別な処理能力が本当に必要でない限り、通常モードで実行するのが最善です。
また、Pythonがデバイスから優れたパフォーマンスを得るための最初の選択肢ではないことに留意することも重要です。 どちらのデバイスもC ++ APIをサポートしています。これは、テストでデバイスから最高のパフォーマンスを得るための「トリック」です。
ソフトウェアサポート
NCS2は、Ubuntu、CentOS、Windows 10などの他のオペレーティングシステムで使用できます。 TensorFlow、Caffe、ApacheMXNet、PyTorch、PaddlePadleをオープンニューラルネットワーク変換によりサポートできます。
CUAはWindowsをサポートしていませんが、Debian 6.0以降(またはUbuntu 10.0+などの派生物)で実行できます。 CUAはTensorFlow Liteモデルを公式にしか実行できないことに言及する価値があります。
サイズ、プロトタイプ設計、その他の詳細の比較
ソフトウェアサポート、計算能力、および消費電力をカバーした後、実際に製品プロトタイプを構築する際の2つの具体的な状況は何ですか?

率直に言って、両方のデバイスは本当にクールに見えます。 CUAは、部分的に透明なボディとヒートシンクのように見える場所を持つ、わずかに銀白色の市松模様のボディです。 NCS2は滑らかな青色のデザインで、青色の本体と統合されたヒートシンクはよりスタイリッシュに見えます。

もちろん、外観は二次的なものです。 重要なのは、NCS2がCUAのように動作し、動作中に熱くなることです。 ただし、そのヒートシンク設計により、真ん中の指で保持する必要なく、クーラー内蔵ヒートシンクに保持できます。これは非常に賢い方法です。
NCS2の設計により、ユーザーは複数のコンピューティングスティックを一緒に使用して処理能力を向上させることができます。 縦型USBドックにきちんと配置できます。 同様に、ホストは複数のCUAを実行できますが、各CUAを保存する別の方法を見つける必要がある場合があります。 両方の寸法が似ていますが、NCS2の厚さ(14 mm)はCUAのほぼ2倍です。 さらに、CUAのような柔軟なケーブルではなく、USBプラグ(特大のサムドライブなど)を介して接続されているため、特定の操作シナリオでは、NCS2を使用するとスペースを非常に扱いにくくなります。 難しい。 データケーブルとドックを広範囲に使用する必要があります。選択する前に、これを検討する必要があります。

最後に、NCS2とCUAは、エッジコンピューティングアプリケーション用に設計された独自のデバイスのようです。 Windowsシステムで実行する必要がある場合、またはTensorflow Liteフレームワークの外部で実行する必要がある場合、NCS2には明確な利点があります。 その一部として、Coral USB Acceleratorの周辺機器はハードウェアをサポートし、よりシンプルで無作法な開発ボードDev Board、Coral Edge TPUベースのPCIアクセラレータ、および開発ボードに似たSoMモジュールをサポートしています。 製品のプロトタイプを迅速に市場に投入する必要がある場合、Coralが最良の選択であり、開発者にとってより魅力的です。

Coral USB Accelerator開発環境の要件:USBポートを備えたLinuxコンピューター、Debian 6.0以降、またはその派生システム(Ubuntu 10.0+など)をサポートする、ARMv8命令セットを備えたx86_64またはARM64システムアーキテクチャ

したがって、上記の要件から、Coral USBアクセラレータはRaspberry Piをサポートしています。 ただし、Raspberry Pi 2/3 Model B / B +であり、Raspbianシステム(または他のDebian派生システム)を実行する必要があります。
この時点で、2つの機能は非常に似ており、Raspberry Piまたは同様のプロジェクトにAI / MLを追加する場合、両方のデバイスが正常に機能します。
多くのプリコンパイルされたネットワークモデルを使用すると、より良い結果をすばやく簡単に取得できます。 それでも、ネットワークを完全に定量化することは依然として高度なタスクです。 変換には、ネットワークとその動作の深い理解が必要です。 さらに、FP_32からFP_16およびFP_16からUINTにアップグレードしたとき、精度に関する損失も大きかった。 興味深いことに、Myriadは浮動小数点の半分を処理でき、CUAは8ビットの浮動小数点しか処理できません。 これは、Myriadがより高い精度を達成できることを意味します。

IntelとGoogleは明らかに2つの異なる「ルーチンを採用しています。Googleの利点は、開発者がプロトタイプを簡単に構築し、Google Cloud Platformからedge-tpuまでの完全なソリューションセットを促進できることです。私は個人的にすべてのコンポーネントが好きです インテルは、開発者がネットワークを最適化してさまざまなハードウェアで実行できるようにするOpenvinoプラグインを提供していますが、OpenVINOは現在、Intel CPU、GPU、FPGA、およびVPUをサポートしています。 課題は、これらの「組み合わせパンチ」が常に各コンポーネントの最適な機能を活用するのに苦労してきたことです。
Google Coral USB Acceleratorは、ネットワークモデルをオンラインでトレーニングできます。これは、転移学習に不可欠です。 明らかに、Googleは、事前にトレーニングされたネットワークと転送の学習が開発者にとって効率的な組み合わせであると考えています。 さらに、Intel NCS2には3組のビルトインステレオデプスハードウェアがあり、障害物回避などの多くのユースケースで役立ちます。
適用シナリオ:
Intel NCS2は、DNNのプロトタイピング、検証、および展開も提供します。 無人および無人車両、およびIoTデバイスには、低消費電力が不可欠です。 ディープラーニング推論アプリケーションの開発を検討しているユーザーにとって、NCS2は最もエネルギー効率が高く、低コストのUSBスティックの1つです。

Google Coralは単なるハードウェアではありません。 カスタムハードウェア、オープンソフトウェア、高度なAIアルゴリズムの機能を簡単に組み合わせて、高品質のAIソリューションを提供します。 Coralには、予測メンテナンス、異常検出、ロボット工学、マシンビジョン、音声認識など、産業開発を支援する多くのアプリケーションケースがあります。 製造、ヘルスケア、小売、スマートスペース、内部監視、輸送部門で優れたアプリケーション価値を持っています。
Google Coral Edge TPUシリーズのハードウェア製品に興味がある場合は、Google CoralエージェントのGravitylinkオンラインストア にアクセスして注文してください。
Google Edge TPUに関する10の質問
1、Edge TPUとは何ですか?
Edge TPUは、低電力デバイス向けの高性能ML推論を提供するGoogleが設計した小さなASICです。 たとえば、MobileNet V2などの最先端のモバイルビジョンモデルをほぼ400 FPSで電力効率の高い方法で実行できます。
2、Edge TPUはどの機械学習フレームワークをサポートしていますか?
TensorFlow Liteのみ。
3、Edge TPUはどのタイプのニューラルネットワークをサポートしていますか?
第一世代のEdge TPUは、畳み込みニューラルネットワーク(CNN)などのディープフィードフォワードニューラルネットワーク(DFF)を実行できるため、さまざまな視覚ベースのMLアプリケーションに最適です。
4、Edge TPUのTensorFlow Liteモデルを作成するにはどうすればよいですか?
モデルをTensorFlow Liteに変換する必要があり、量子化対応トレーニング(推奨)またはトレーニング後の完全整数量子化を使用してモデルを量子化する必要があります。 (トレーニング後の量子化と互換性のあるモデルを作成するには、TensorFlow 1.15を使用し、入力と出力の両方のタイプをuint8に設定する必要があります。現在、floor入出力のみをサポートするため、TensorFlow 2.0は使用できません。 Edge TPUとの互換性のためのモデル。
ただし、画像分類アプリケーションを構築している場合は、Cloud AutoML Visionを使用して、Edge TPUと互換性のあるモデルを簡単に構築することもできます。このWebベースのツールは、独自の画像を使用してモデルをトレーニングし、モデルを最適化してからEdge TPUにエクスポートするためのグラフィカルUIを提供します。
5、TensorFlow 2.0を使用してモデルを作成できますか?
はい、TensorFlow 2.0とKeras APIを使用してモデルを構築し、トレーニングできます。ただし、モデルをTensorFlow Lite形式に変換する場合は、v1.15からのTensorFlow Liteコンバーターを使用して、トレーニング後の量子化を実行する必要があります。これは、TensorFlow 2.0のTFLiteConverterが現在、量子化中にuint8入力および出力テンソルをサポートしていないためです。これはEdge TPUで必要です。また、TensorFlow 2.0は現在、量子化に対応したトレーニングをサポートしていません。
6、Edge TPUの処理能力はどのくらいですか?
Edge TPUは、1秒あたり4兆回の操作(テラ操作)(TOPS)を実行でき、各TOPSに0.5ワット(1ワットあたり2 TOPS)を使用します。
7、Edge TPUは加速MLトレーニングを実行できますか?
はい、ただし最終層の再トレーニングのみ。 TensorFlowモデルはEdge TPUで高速化するためにコンパイルする必要があるため、後ですべてのレイヤーの重みを更新することはできません。 ただし、2つの異なる方法で高速転送学習を実行するAPIを提供しています。
クロスエントロピー損失関数を使用して、最終的に完全に接続されたレイヤーだけの重みを更新する逆伝播。
新しいデータからの画像埋め込みを使用して最終層に新しい活性化ベクトルを刷り込む重み刷り込み。これにより、非常に小さな小さなデータセットで新しい分類を学習できます。
8、Dev BoardとUSB Acceleratorの違いは何ですか?
Coral Dev Boardは、SOCとEdge TPUがSOMに統合されたシングルボードコンピューターであるため、完全なシステムです。 また、SOMを削除(または個別に購入)し、3つのボード間コネクタを介して他のハードウェアと統合することもできます。
このシナリオでも、SOMにはSOCとEdge TPUを備えた完全なシステム、およびすべてのシステムインターフェイス( I2C、MIPI-CSI / DSI、SPIなど)は、基板間コネクタの300ピンを介してアクセスできます。
一方、Coral USB Acceleratorは、エッジTPUをコプロセッサとして既存のシステムに追加するアクセサリデバイスです。USBケーブルを使用してLinuxベースのシステムに接続するだけで済みます(最高のパフォーマンスを得るにはUSB 3.0をお勧めします)。
9、Edge TPUチップだけを購入できますか?
いいえ、現在、スタンドアロンのEdge TPU ASICは提供していませんが、USB 3.0またはPCI-Eインターフェイスを使用して、既存のハードウェアシステムのコプロセッサーとしてEdge TPUを簡単に統合できる2つの製品を提供しています。 詳細については、以下の製品リストを参照してください。
10、すべてのGoogle Edge TPU製品

開発ボード
Edge TPUを備えたリムーバブルシステムオンモジュール(SoM)を備えたシングルボードコンピューター。
USBアクセラレーター
ML推論を既存のシステムにもたらすEdge TPUを備えたUSBアクセサリ。
開発ボードミニ
ミニPCIeアクセラレーター
Edge TPUを既存のシステムに簡単に統合できるPCIeデバイス。
M.2アクセラレータA + E/B+Mキー
Edge TPUを既存のシステムに簡単に統合できるPCIeデバイス。
システムオンモジュール(SoM)
40mm x 48mmのプラガブルモジュール内の高速MLアプリケーション用の完全に統合されたシステム。
加速器モジュール
Edge TPUを含むはんだ付け可能なマルチチップモジュール
Google Coral製品、および#Gravitylinkオンラインストア(https://store.gravitylink.com/global) での大量販売または大量販売(ボリュームディスカウント)の詳細に興味がある場合は、メールでセールスチームにお問い合わせください。 sales@gravitylink.comまたはmarket@gravitylink.comにご連絡ください。できるだけ早く見積もりをお送りします。
オンデバイスインテリジェンスのためのGoogle Coral Edge TPUソリューション
AI は今日、コンシューマ アプリケーションからエンタープライズ アプリケーションに至るまで広く使用されています。接続デバイスの急激な増加と、プライバシーや機密性保持、低レイテンシ、帯域幅の制約に対する要求があいまって、クラウドでトレーニングした AI モデルをエッジで実行する必要性が高まりつつあります。Edge TPU は AI をエッジで実行する目的に特化して Google が設計した専用 ASIC です。低消費電力、小フットプリントで高パフォーマンスを実現し、高精度の AI をエッジにデプロイできます。
Edge TPU は予測メンテナンスや異常検出、マシaンビジョン、ロボット工学、音声認識など、増え続ける産業ユースケースに使用できます。 また、製造、オンプレミス、ヘルスケア、小売、スマート スペース、交通機関などにも使用できます。
Coralは、新世代のインテリジェントデバイスを可能にします。
Google CoralのすべてのハードウェアはGravitylinkオンラインストアで入手できます。
Gravitylink は、Google Coralのグローバルボリュームディストリビューターです。
Google Coral製品、および大量販売または大量販売(ボリュームディスカウント)の詳細については、sales @ gravitylink.comまたはmarket@gravitylink.comにメールでお問い合わせください。 私達の最もよい引用をできるだけ早くあなたに。
Coralは、ローカルAIを使用して製品を構築するための完全なツールキットです。 デバイス上の推論機能により、効率的、プライベート、高速、オフラインの製品を構築できます。
新興企業や大規模企業に十分な柔軟性
オンデバイスインテリジェンスのためのGoogle Coralソリューション
物体検出:
画像内で認識されているさまざまなオブジェクトの位置の周りに正方形を描きます。
ポーズ推定:
さまざまな身体の関節を識別することにより、画像内の人々のポーズを推定します。
画像のセグメンテーション:
画像内のさまざまなオブジェクトとその位置をピクセルごとに識別します。
キーフレーズ検出:
オーディオサンプルを聞いて、既知の単語やフレーズをすばやく認識します。
製品に最適なフォームファクターでMLを高速化します。 プロトタイピングデバイスには、シングルボードコンピューターとUSBアクセサリが含まれます。 実稼働対応デバイスには、システムオンモジュールとPCIeモジュールが含まれます。

新しいGoogle CoralハードウェアがGravitylink Storeでリリースされました!
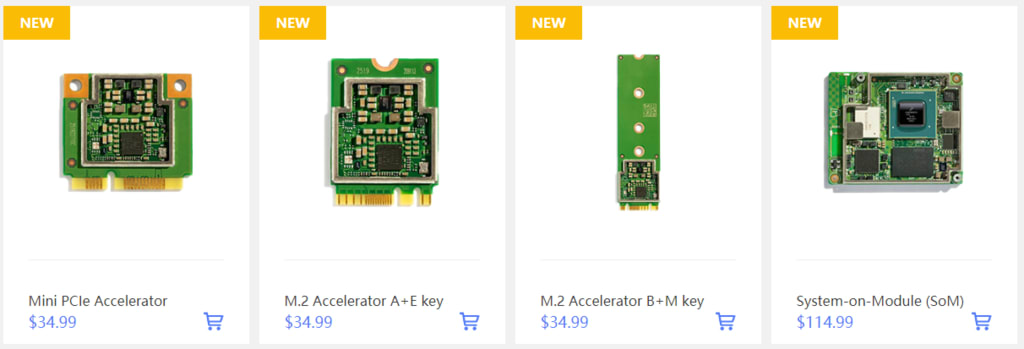

Edge TPUを既存のシステムに簡単に統合できるPCIeデバイス。
Coral Mini PCIe Acceleratorは、Edge TPUコプロセッサーを既存のシステムと製品にもたらすPCIeモジュールです。
Coral Mini PCIe Acceleratorは、Edge TPUコプロセッサーを既存のシステムと製品にもたらすPCIeモジュールです。

Mini PCIe Acceleratorは、標準のMini PCIeスロットに収まるように設計されたハーフサイズのMini PCIeカードです。 このフォームファクタにより、ARMおよびx86プラットフォームに簡単に統合できるため、組み込みプラットフォーム、ミニPC、産業用ゲートウェイなどの製品にローカルMLアクセラレーションを追加できます。
Google Coral Edge TPU M.2アクセラレーター(A + E / B + Mキー)


M.2 A + E / B + Mキーインターフェイスを使用して、Edge TPUをレガシーシステムと新しいシステムに統合します。
Coral M.2アクセラレータは、既存のシステムおよび製品にEdge TPUコプロセッサーを提供するM.2モジュールです。
Coral M.2アクセラレータは、既存のシステムおよび製品にEdge TPUコプロセッサーを提供するM.2モジュールです。
M.2アクセラレータはデュアルキーM.2カード(A + EまたはB + Mキー)で、互換性のあるM.2スロットに適合するように設計されています。このフォームファクタにより、ARMおよびx86プラットフォームに簡単に統合できるため、組み込みプラットフォーム、ミニPC、産業用ゲートウェイなどの製品にローカルMLアクセラレーションを追加できます。
環境センサーボード

IoTアプリケーションに温度、光、湿度センサーを提供するアクセサリボード。
環境センサーボードは、Coral Dev BoardまたはRaspberry Piプロジェクトにセンシング機能を追加するアドオンボード(pHATまたはボンネットとも呼ばれます)です。 (Raspberry Piボードとの互換性のためにEEPROMが含まれています。)
ボードは、光レベル、気圧、温度、湿度などの大気データを提供します。 Groveコネクタを使用して追加のセンサーを取り付けることもできます。
ボードには、Googleキーを備えた安全な暗号プロセッサも含まれており、Google Cloud IoT Coreサービスとの接続が可能になり、デバイスに安全に接続し、センサーデータを収集、処理、分析できます。
CoralおよびRaspberry Piボードと互換性があります。
環境センサーボードは、Coral Dev BoardまたはRaspberry Piプロジェクトにセンシング機能を追加するアドオンボード(pHATまたはボンネットとも呼ばれます)です。 (Raspberry Piボードとの互換性のためにEEPROMが含まれています。)
ボードは、光レベル、気圧、温度、湿度などの大気データを提供します。 Groveコネクタを使用して追加のセンサーを取り付けることもできます。
ボードには、Googleキーを備えた安全な暗号プロセッサも含まれており、Google Cloud IoT Coreサービスとの接続が可能になり、デバイスに安全に接続し、センサーデータを収集、処理、分析できます。
CoralおよびRaspberry Piボードと互換性があります。
システムオンモジュール(SoM)

40mm x 48mmのプラガブルモジュールで、高速化されたMLアプリケーション(CPU、GPU、Edge TPU、Wi-Fi、Bluetooth、およびSecure Elementを含む)用の完全に統合されたシステム。
Coral System-on-Module(SoM)は、高速機械学習(ML)推論を必要とする組み込みシステムの構築を支援する完全統合システムです。 NXPのiMX8Mシステムオンチップ(SoC)、eMMCメモリ、LPDDR4 RAM、Wi-Fi、およびBluetoothが含まれていますが、その独自のパワーはGoogleのEdge TPUコプロセッサーから得られます。
Edge TPUは、Googleが設計した小さなASICであり、低電力コストで高性能なML推論を提供します。 たとえば、MobileNet v2などの最先端のモバイルビジョンモデルを400 FPSで電力効率の高い方法で実行できます。 このオンデバイス処理により、レイテンシが削減され、データプライバシーが向上し、クラウドでML推論を実行するために使用される高帯域幅接続の必要性がなくなります。
Coral System-on-Module(SoM)は、高速機械学習(ML)推論を必要とする組み込みシステムの構築を支援する完全統合システムです。 NXPのiMX8Mシステムオンチップ(SoC)、eMMCメモリ、LPDDR4 RAM、Wi-Fi、およびBluetoothが含まれていますが、その独自のパワーはGoogleのEdge TPUコプロセッサーから得られます。
Edge TPUは、Googleが設計した小さなASICであり、低電力コストで高性能なML推論を提供します。 たとえば、MobileNet v2などの最先端のモバイルビジョンモデルを400 FPSで電力効率の高い方法で実行できます。 このオンデバイス処理により、レイテンシが削減され、データプライバシーが向上し、クラウドでML推論を実行するために使用される高帯域幅接続の必要性がなくなります。
Google Coral製品に興味があり、#Gravitylinkオンラインストア(https://store.gravitylink.com/global)での大量販売または大量販売(ボリュームディスカウント)の詳細については、メールで営業チームにお問い合わせください。 sales@gravitylink.comまたはmarket@gravitylink.comにご連絡ください。できるだけ早く見積もりをお送りします。

