新しいRaspberry Pi 4、モデルBでのTensorFlow Liteのベンチマーク
Raspberry Pi 4が発売されたとき、私はエッジでの機械学習を目的とした新世代のアクセラレータハードウェアのためにまとめてきたベンチマークを更新するために座った。 残念ながら、Raspberry Pi 4のリリースに対応したTensorFlowホイールのバージョンがありましたが、TensorFlow Liteのコミュニティビルドにはまだ問題がありました。(作者:Alasdair Allan)

それはちょうど変わったので、ここに行きます...
ベンチマークの結果の見出し
TensorFlow Liteを使用すると、完全なTensorFlowを使用した以前のベンチマークの元の結果と比較すると、かなりの速度の向上が見られます。
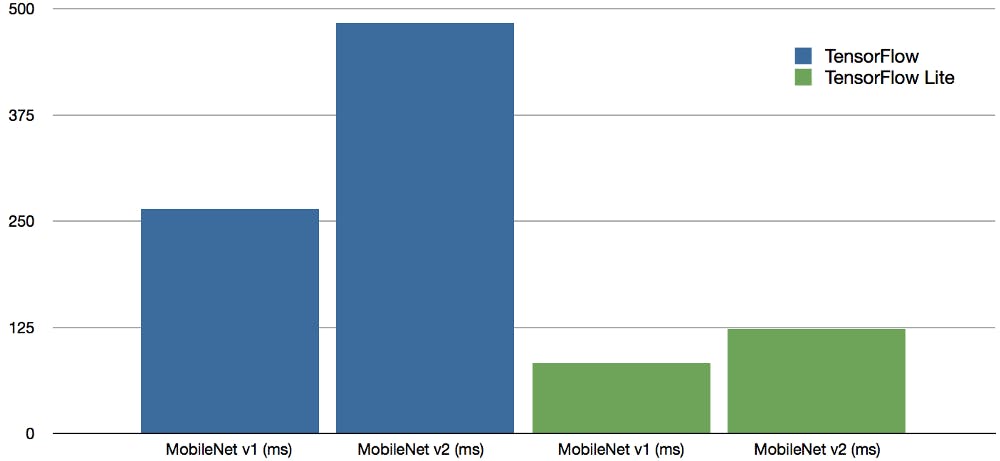
新しいRaspberry Pi 4モデルの入力サイズ300×300のコンテキスト内の共通オブジェクト(COCO)データセットを使用してトレーニングされたMobileNet v1 SSD 0.75深度モデルとMobileNet v2 SSDモデルのベンチマーク結果はミリ秒単位 B、実行中のTensor Flow(青)およびTensorFlow Lite(緑)。
元のTensorFlowベンチマークとTensorFlow Liteを使用した新しい結果との間で、推論速度が3倍から4倍向上していることがわかります。 この推論時間の短縮により、Raspberry Pi 4はNVIDIA Jetson Nanoと直接競合します。
結果のより詳細な分析
ベンチマークは、Raspberry Pi 3、モデルB +、および4GBバージョンのRaspberry Pi 4、モデルBでTensorFlowとTensorFlow Liteの両方を使用して行われました。 TensorFlow Liteに変換されたコンテキスト内の共通オブジェクト(COCO)データセットでトレーニングされたモデル。
フレームに2つの認識可能なオブジェクト、バナナとリンゴを含む単一の3888 x 2916ピクセルのテスト画像を使用しました。 画像は、モデルに表示する前に300 x 300ピクセルにサイズ変更され、平均推論時間が取られる前に各モデルが10,000回実行されました。 ロードのオーバーヘッドにより時間がかかる最初の推論実行は破棄されました。
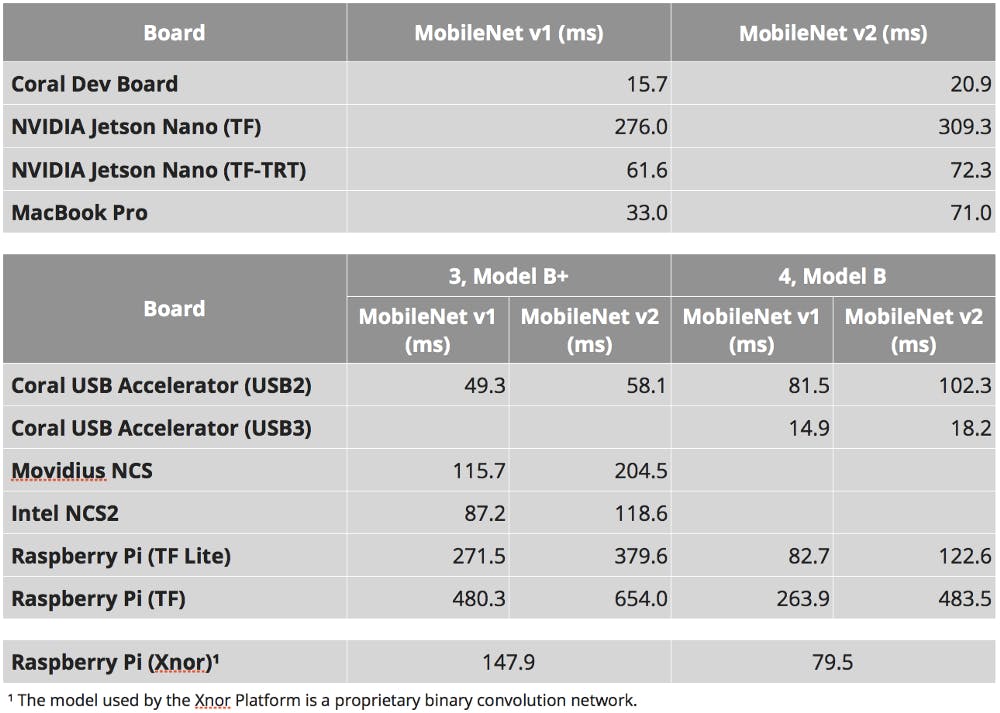
ベンチマークの結果は、入力サイズ300×300のコンテキスト内の共通オブジェクト(COCO)データセットを使用してトレーニングされたMobileNet v1 SSD 0.75深さモデルとMobileNet v2 SSDモデルのミリ秒単位です。 Xnor.ai AI2GOプラットフォームの結果は、独自のバイナリコンボリューションネットワークを使用しています。
⚠️警告Raspberry Pi 4の以前の結果によると、Raspberry PiのGPIOヘッダーから駆動される小さなファンの追加は、CPU温度を安定させ、CPUの熱スロットルを防ぐ必要がありました。
これらの結果は、以下のプラットフォームで以前に取得したベンチマーク結果と比較できます。 Coral Dev Board、NVIDIA Jetson Nano、Raspberry Piを搭載したCoral USBアクセラレーター、Raspberry Piを搭載した元のMovidus Neural Compute Stick、Raspberry Piを搭載した第2世代Intel Neural Compute Stick 2 独自のバイナリ畳み込みネットワークを使用して、Xnor.ai AI2GOプラットフォームとの比較も行いました。
- 情報:Raspberry Pi 3、モデルB +はUSB 3をサポートしていないため、Raspberry Pi 3でUSBを使用するCoral USBアクセラレーターでは結果が利用できません。
StickとIntel Neural Compute Stick 2は、Raspberry Pi 4、Model Bでは使用できません。IntelOpenVINOフレームワークはPython 3.7ではまだ動作しません。 近い将来、Raspberry Pi 4でのIntel Neural Compute Stickの公式サポートを期待しないでください。
新しいRaspberry Pi 4での最初のTensorFlowの結果は、パフォーマンスが2倍向上したことを示しています。 NEONの容量はRaspberry Pi 3の2倍であるため、これはおおむね予想と一致しています。よく書かれたNEONカーネルのパフォーマンスがこの順序で高速化されると予想されます。
しかし、TensorFlow Liteを使用すると、TensorFlowベンチマークとTensorFlow Liteを使用した新しい結果との間で推論速度が3〜4倍速くなり、TensorFlow Liteの速度が大幅に向上します。 この結果は、2つのパッケージ間でパフォーマンスが2倍しか向上していないRaspberry Pi 3で同様の比較を行ったときよりもはるかに大きくなっています。 したがって、Raspberry Pi 4でTensorFlowを介してTensorFlow Liteを使用すると、予想される速度のほぼ2倍の速度が得られます。
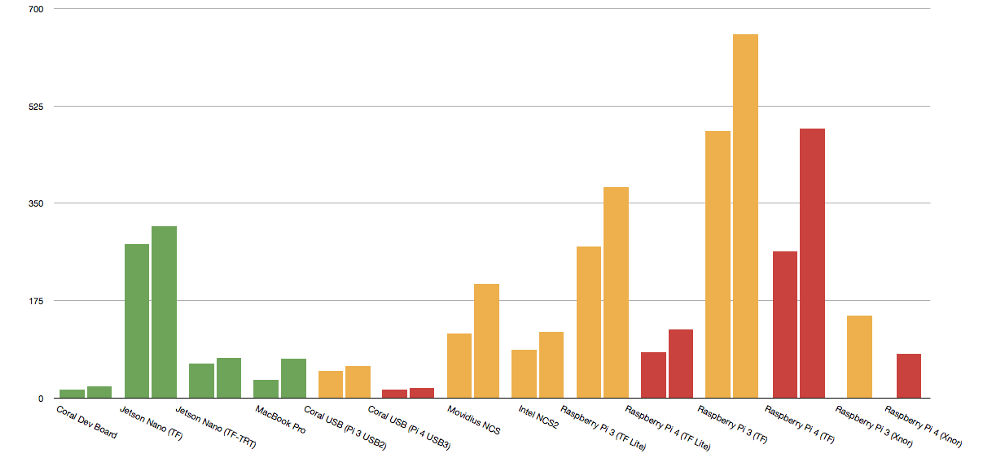
この推論時間の短縮により、Raspberry Pi 4は、NVIDIA Jetson NanoとIntelのMovidiusベースのハードウェアの両方と直接競合します。
⚠️警告:Movidius Neural Compute StickとIntel Neural Compute Stick 2は、USB 2ではなくUSB 3を使用してRaspberry Pi 4に接続すると、パフォーマンスが向上する可能性があります。ただし、OpenVINOフレームワークがPython 3.7をサポートするまで、知ることはできません。確かに。現在、IntelのMovidiusベースのハードウェアはRapsberry Pi 4では使用できません。
機械学習に使用するNVIDIA Jetson Nanoの購入を検討している場合、Raspberry Pi 4が同様のレベルで実行されますが、半分のコストで実行できる理由はないようです。
概要
新しいRaspberry Pi 4で見られるパフォーマンスの向上により、エッジでの機械学習推論のための非常に競争力のあるプラットフォームになります。 Raspberry Pi 4のTensorFlow Liteで見られる推論パフォーマンスの向上は、NVIDIA Jetson NanoおよびIntel Neural Compute Stick 2との競合に直接つながります。
1GBバージョンが35ドル、4GBバージョンが55ドルの新しいRaspberry Pi 4は、どちらも99ドルのNVIDIA Jetson NanoとIntel Neural Compute Stick 2の両方よりも大幅に安価です。特に、Compute Stickの場合、このコストはRaspberry Pi自体のコストに追加されるため、合計134ドルになります。

GoogleのCoral Dev Boardは依然として「クラス最高」のボードですが、Raspberry Pi 4にUSB 3が追加されたことにより、Dev Boardとの価格競争力も強化されました。価格が35ドルの新しいRaspberry Pi 4の1GBバージョンは、149ドルのCoral Dev Boardよりも大幅に安価です。 Coral USB Acceleratorに74.99ドルをRaspberry Piの価格に追加すると、109.99ドルのコストで以前の「クラス最高」のボードを上回ることができます。パフォーマンスを向上させるために、Coral Dev Boardのコストを39.01ドル節約します。

- GoogleのCoral海外代理店:https://store.gravitylink.com/global